If you are the regular reader of my blog, you may notice that I’ve unpublished a recent series of rants over the current and escalating war between Automattic (really, Matt Mullenweg himself) and WP Engine.
I’ve unpublished them because they were angry and unfocused rants, as I struggled to get a handle on why what is happening is happening, and what it really means to (and for) me, as well as the larger WordPress community.
This afternoon I channeled that frustration into some long-overdue household tasks — fixing a kitchen cabinet door, shampooing the carpet in the upstairs hallway, clearing out the clogged drain of a bathroom sink — and those few hours of manual labor gave me time to sift through the thoughts and feelings piling up in my brain.
I realized that the heart of the matter is a lack of common agreement on the nature of free open source software (FOSS) — specifically, both the ethics and the economics of FOSS. Now that I’ve realized what is at the heart of my recent frustration and anger, I can start thinking — and writing — more constructively about it, rather than firing off aimless missives.
A more coherent mini-essay on this topic is forthcoming. But for now, the earlier angry posts are unpublished. Gone, but not forgotten. And, well, not really gone. Thanks to WordPress.
Stay tuned…
In the meantime, read this. Then this. Then consider this.
The folly of blog-centric “author” functionality in the context of a modern WordPress-based, non-blog website
This week’s article on The Verge about the latest messy drama in the WordPress world (tl;dr it’s Matt Mullenweg vs. WP Engine, and if you’ve read any of my previous writings about WordPress you can probably guess whose side I’m on in that fight) got me thinking once again about how Matt really doesn’t understand his creation.
And yes, I’m personifying the entire core team in Matt. But, let’s be serious. He kind of does that himself.
Anyway, today I got an email from a long-time client who uses WordPress and WooCommerce — which, fun fact, is now owned by Automattic, the company that not only is the primary supporter of the open source WordPress project, but is “cleverly” named after Matt himself! — describing a weird situation.
This client’s WooCommerce site has been running for ages. Well over a decade. And a lot of their products have been on the site with minimal edits for years. But this client noticed a few days ago that a large number of those products had suddenly lost their images, and he was hoping I could get to the bottom of it.
Fortunately, I have the excellent Simple History plugin installed on the site, so I was able to go back and investigate the recent activity.
Much to my surprise, I found that this client himself had deleted all of those product images a week ago. At first I jumped to the conclusion that his account had been compromised. But I noticed that the IP address he was logged in from matched the local ISP his business uses. So, it sure seemed to be him.
I scrolled through pages and pages of logs just like this, all with timestamps in a span of 3 minutes:
Finally, at the end of that list, there was this:
Now I understood what was going on.
Once again it’s a situation where the origins of WordPress as blogging software come back to bite it. Or rather, me. And my clients.
There’s a lot of functionality around “authors” in WordPress that really only makes sense if the site is a blog — a blog with multiple authors. Like the fact that author archive pages exist. Even if your site isn’t a blog. And that, unless you take steps to shut these off, e.g. with a plugin, every user with author- or higher access automatically has an author archive page that shows all of the posts they published on the site.
Do you want that? Do you even know it exists? I’ve made my living in the WordPress ecosystem for more than a decade and even I usually forget it’s a thing.
But there’s something even worse…
Uh-oh.
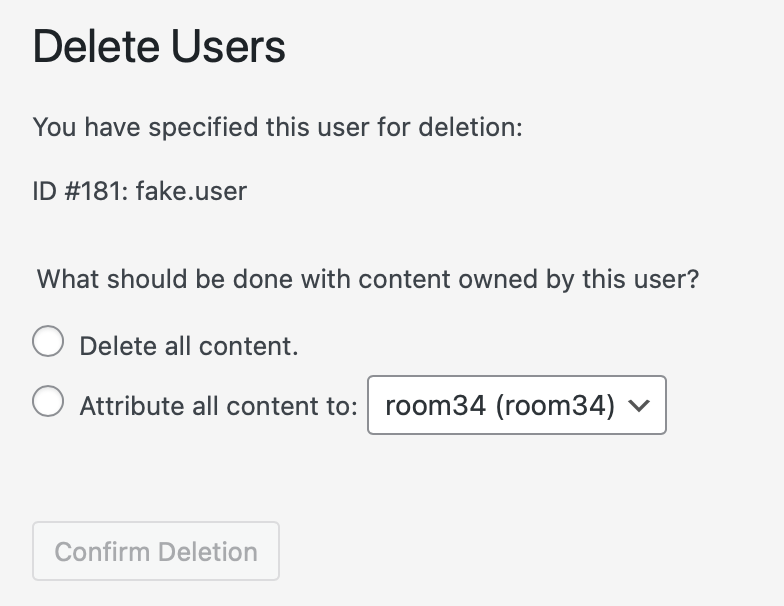
Does the average WordPress site admin (not developer, just an ordinary site admin) really understand what content ownership means in WordPress?
Is it reasonable to assume that someone faced with this screen truly understands that clicking that Delete all content radio button is going to delete all of the images in the Media Library that this user ever uploaded, even to posts (and remember, WooCommerce products are “posts”) that they didn’t initially create?
Because that’s what it’s about to do.
In fact, that is exactly what it did do to my client last week. And now I’m working on a way to restore those deleted images.
Well, what should WordPress do in this situation?
For starters, the text of the options could be a lot more explicit about the implications of the choice. The radio button for attributing the content to another user — ideally whatever Administrator-role account’s email address matches the primary admin email, if one exists — could be pre-selected as the default. There absolutely should be a confirmation dialog warning, in scary language, that anything the user ever created, including file uploads to the Media Library, will be deleted permanently.
Or, maybe it could be “smarter” on a whole other level, and adapt contextually so that when the site is clearly not using the blog author functionality, it would not even present this option. Just un-assign the authorship meta data, but keep the content. At least for Media Library files.
So, now what?
Fortunately, the site is hosted at WP Engine (remember them?) and they automatically make daily backups of every site. Downloading the backup from the day before all this went down was the easy part. But since a week has gone by and the client has been busy updating the site, I can’t just restore the backup… they’d lose all their work (plus all of the details of orders that came in over the same week). So I need to find a way to reimport the relevant images and remap them to the products.
Also fortunately, I’ve done a ton of direct, hands-on work in MySQL databases over the years, so I think I’ll be able to pretty quickly narrow down the list of products that “lost” their images last week, as well as which images those were. Getting them reassigned where they belong though may not be so easy.
That’s been Matt’s cute little tagline on his own WordPress blog since the dawn of time, but I feel like we’re the unlucky ones.
Update, a while later: Instead of leaving this post as an unresolved rant, I decided to make something constructive out of it and write up how I restored the images.
First I went into WP Engine’s Backups section, and used the Prepare ZIP option on the backups from both the day before and the day after the incident. I chose to download the database and the uploads directory. I left the plugins and themes directories out of it, because they’re not relevant here, and I’ve got enough to deal with already.
Once I downloaded and extracted the two zip files, which — no joke — took over a half hour even on my fiber gigabit connection, I put them into two adjacent folders on my Mac desktop, and then in Terminal I ran the following command:
diff -rq folder1 folder2 > differences.txt
The actual folder names should be subbed in for the black text. This gave me a file called differences.txt that listed all of the files in the old archive that were not in the new archive. I opened the file in BBEdit for further processing.
Of course, this list included all of the scaled-down versions of the images, and I only really want the source images. WordPress appends the dimensions of each scaled-down image into the filename before the extension, so I was able to use BBEdit’s Process Lines Containing… tool to filter those out with a grep. (Note: This regular expression is a little rough, because it assumes that you didn’t upload any images that included a string consisting of a hyphen, some digits, an x, some more digits, and a period.)
-[0-9]+x[0-9]+\.
Since I’m on a Mac and had already been mucking around in those folders in the Finder, I also had to run the tool again to delete the inevitable .DS_Store files.
Inside the parent folder for the old archive, adjacent to the uploads directory, I created a new director called images-to-restore where I intended to put all of the images I… need to restore. Then I ran a find-and replace on the remaining lines in the text file in BBEdit to turn it into a series of commands in this format:
Obviously the part in black was unique for each line. And, of course, this is assuming they never uploaded files with the same filename in different months. (Hint: They did, of course they did, and I won’t realize that until much later in the process.) I will leave it for the reader to determine the most efficient way to modify this cp command to avoid overwriting duplicates.
I saved this to a new file in that same directory called script.sh and in the Terminal, gave it execute permission. Then… I ran it. Boom, within a second, the 531 deleted images were all gathered in one place, ready to upload back into the Media Library.
This is where I stopped for the night. It was already 6 PM, and I needed a fresh start to figure out the database portion.
Update #2, the next morning: OK, how is this database portion going to work? All 531 images are now in the Media Library, but I have two main challenges here:
Figuring out how WooCommerce handles the main Product Image. Is it just a relabeling of the standard Featured Image, as it seems to be? Answer: Yes. So, how are those handled in the database? In the wp_postmeta table, there are records with the product ID in the post_id field, '_thumbnail_id' in the meta_key field, and the attachment ID in the meta_value field. Knowing that, I can move on to…
Figuring out how to map the new attachment IDs for the re-uploaded images to the correct product IDs. This is involved enough that I need to break out of the ordered list, so… here we go, back to regular paragraphs.
Before I continue… if you are getting the impression that I’m writing this as I go through the process, you’re absolutely correct. And that will come back to bite me.
Along with the images themselves, I downloaded copies of the database from the days immediately before and after the incident. The problem is, running a diff in BBEdit on two large (360 MB) SQL files is not going to be very useful. I need to just load those tables into a sandbox database and run some queries against them.
First, I used BBEdit to cut out just the tables I need (wp_posts and wp_postmeta), from the rest of the SQL files. I also did a find-and-replace to change the table prefixes so I could put both versions into the same database and easily tell them apart. I used wp22_ and wp24_ as the prefixes, to match the before-and-after dates.
There are two ways I could handle this next step. Since I have a list of the filenames I re-uploaded, I could search on those. Or, I could search for attachment-type posts in wp22_ that are missing in wp24_. I went with that approach since it’s much cleaner:
SELECT ID, guid FROM wp22_posts WHERE post_type = 'attachment' AND ID NOT IN (SELECT ID FROM wp24_posts WHERE post_type = 'attachment');
(Note: I conventionally wrap table and field names in backticks, but that’s not technically required — unless their names match a SQL command keyword, which good database designers know not to do anyway — and since the Block Editor uses the backtick character as a shortcut to jump into and out of “inline code” mode, I had to omit them here.)
All I really needed was the ID field, but I brought in the guid field as well so I can do a sanity check. That field contains the full direct URLs to the images in the Media Library.
This query only returned 529 records, not the 531 I was expecting, but I’m not too worried about that. Even if I’ve lost the mapping for two images along the way, this is going to get my client back 99.6% of the missing images. Eventually they’ll find the two products that still don’t have images, and since those images are back in the Media Library now, it’ll be easy to fix them manually. (Or, it’s possible that only 529 products are missing images and the other two images are something random.)
Of course, I also need to know the new attachment IDs for the re-uploads. So I went into the current version of the database and extracted the wp_posts and wp_postmeta tables there too. (I left their prefixes unchanged.) There’s a useful record in the wp_postmeta table, with a meta_key of '_wp_attached_file'. That’s the relative URI for the original image file, under the site’s wp-content/uploads directory.
In the “current” table, I’m just going to search for attachments I (user ID 1) uploaded yesterday:
SELECT ID, guid FROM wp_posts WHERE post_type = 'attachment' AND post_author = '1' AND post_date LIKE '2024-09-30%';
The trick of course is that the guid records are not going to be the same, thanks to how WordPress sorts uploads into year- and month-based subdirectories. (Also, I’m assuming they never uploaded two images with the same filename in different months. But again we’re back to just trying to resolve the bulk of the problem. I’m not going for 100% perfection.)
What I need is a way to find just the filename portion of the guid URL value. Fortunately, there’s a way to do that in MySQL, and even though my SQL skills are rusty, my googling1 skills aren’t, so I found a solution courtesy of StackOverflow. It’s the SUBSTRING_INDEX() function.
So, here’s my way of finding a mapping of the old attachment IDs to the new attachment IDs, using that function. Note that I’m only bothering with using the second of the above queries (reduced to one operand to avoid MySQL error #1241) in narrowing down the list, because that’s all I really need to do with an INNER JOIN.
SELECT wp22_posts.post_parent AS product_id, SUBSTRING_INDEX(wp22_posts.guid, '/', -1) AS filename, wp22_posts.ID AS old_id, wp22_posts.guid AS old_guid, wp_posts.ID AS new_id, wp_posts.guid AS new_guid FROM wp22_posts INNER JOIN wp_posts INNER JOIN wp22_postmeta ON wp22_postmeta.post_id = wp22_posts.ID AND wp22_postmeta.meta_key = '_wp_attached_file' WHERE SUBSTRING_INDEX(wp22_posts.guid, '/', -1) = SUBSTRING_INDEX(wp_posts.guid, '/', -1) AND wp_posts.ID IN (SELECT ID FROM wp_posts WHERE post_type = 'attachment' AND post_author = '1' AND post_date LIKE '2024-09-30%');
RRRRRRRRRRIP…
That was the moment when I realized that the client did, in fact, upload quite a few different images with the same filename over the years. And since I didn’t account for that in my shell script yesterday, those got flattened down to just one instance each. Fortunately, the problem isn’t as bad as I initially feared. This mapping query returned 558 results. That’s 29 more than I expected, and it corresponds to 29 duplicate filenames. But, the wp22_posts.post_parent field (labeled as product_id for clarity for myself), which corresponds to the product records the images are actually attached to, returned a lot of 0 values. What that means is, the products those images were associated with had already been deleted at some point. That was 205 of the total 558 records, bringing the number of products I actually need to “fix” down to 353, and among those I was only able to find 7 duplicate filenames. So we’re at 98.0% now.
Most importantly, with this narrowed down list, I also now have a direct mapping of the product IDs to the new attachment IDs. I copied just the product_id and new_id columns from the spreadsheet and pasted them into BBEdit, to generate my list of SQL UPDATE statements.
Maybe there’s a better way to do this, but this is how I’ve always handled it. Now I have a text document in BBEdit with a pair of numbers on each line, with some tabs in between. Some careful use of find-and-replace can turn those tabs and line breaks into a series of individual UPDATEs that will look like this:
UPDATE wp_posts SET post_parent = 111528 WHERE ID = 118861 AND post_parent = 0 LIMIT 1;
The AND parent_id = 0 LIMIT 1 portion is just kind of a safety check. It means that I won’t modify any records that already have a post_parent set, and that each update will only affect one row. (I mean, that’s really redundant because the WHERE ID = clause necessarily limits it to one row since ID is the primary key of the table. But better safe than sorry.
I ran the batch of UPDATEs in my sandbox database first and did some spot checks to make sure the correct post_parent values had gotten assigned to the newly re-uploaded image records. It checked out, so I went ahead and ran it on the live database. Fingers crossed…
Oh, but before I ran it on the live database, I backed up the table. That’s a lesson I learned the hard way, many years ago.
And…
It didn’t work.
Well now, hang on a second. Maybe the problem is that I missed a step. That’s right, back to #1 from today’s to-do list. I need to create those '_thumbnail_id' records in the wp_postmeta table.
Back to the old database to cross-reference these:
SELECT post_id as product_id, meta_value as old_id FROM wp22_postmeta WHERE meta_key = '_thumbnail_id' AND meta_value IN (SELECT ID FROM wp22_posts WHERE post_type = 'attachment' AND ID NOT IN (SELECT ID FROM wp24_posts WHERE post_type = 'attachment'));
Now that’s the simple version, just to make it reasonable to grasp what’s going on. It’s only returning the product IDs along with the old attachment ID associated as the featured image. But I need to map these to the new image IDs. That’s going to require merging in that really complicated query from above.
Honestly, trying to think that through started to melt my brain, so I decided to take a novel approach. You can make up whatever meta data you want. So I decided to insert a new type of meta data in the current database, to store the mappings of the old IDs to the new ones. Back to my BBEdit find-and-replace approach, pulling the old and new IDs in and generating a set of INSERT statements like this:
INSERT INTO wp_postmeta (meta_key, meta_value, post_id) VALUES ('_recovery_20240930_old_id', old_id, new_id);
With that step completed, I’m able to short-circuit further exploration and jump straight to the following update statement. In the interest of time, I once again blasted through a BBEdit find-and-replace. I believe it’s possible to do this with a single UPDATE statement with the correctly chosen subqueries, but I’m running out of time so I need to resort to the quick-and-dirty approach. (Note, this turned out not to require those '_recovery_20240930_old_id' meta data records at all, but they’re nice to have for possible future reference anyway… and they’d be essential to the smarter, single-query solution.)
I discovered that as I had worked with a few of the products, their meta records for _thumbnail_id had already been deleted, so the best approach was to delete all of the associated _thumbnail_id records, and then insert new ones.
DELETE FROM wp_postmeta WHERE meta_key = '_thumbnail_id' AND meta_value IN (…) LIMIT 353;
The ellipses should be replaced with a comma-delimited list of the “old” attachment IDs. Then, blast through BBEdit find-and-replace again to create insert statements like the following, mapping the new attachment IDs to the associated product IDs:
INSERT INTO wp_postmeta (meta_key, post_id, meta_value) VALUES ('_thumbnail_id', 114396, 118771);
It worked! Of course, there are a bunch of products with multiple images and those are not yet reassigned to the WooCommerce galleries, but at least all — or almost all — of the products now have a featured image again so the WooCommerce “missing image” placeholder isn’t showing up everywhere.
If you don’t know what Elementor is, good. If you do, you probably either hate it too, or else you’ve never used WordPress without it. (And even if you haven’t ever used WordPress without it, you still might hate it.)
In my experience, Elementor is hot garbage, and it makes the overall WordPress experience bad.
It’s not just Elementor. There are several “page builder” plugins for WordPress, and they’re all terrible. Divi, WP Bakery, Beaver Builder, etc. They all deviate wildly from the way WordPress is intended to work. Since 2018 WordPress has had the Block Editor (a.k.a. Gutenberg) built-in, which is essentially a page builder itself. Now that Gutenberg has matured enough to be useful, those other page builders are completely unnecessary.
Among the page builders, I think Elementor is the worst. Why? Mainly because of its ubiquity.
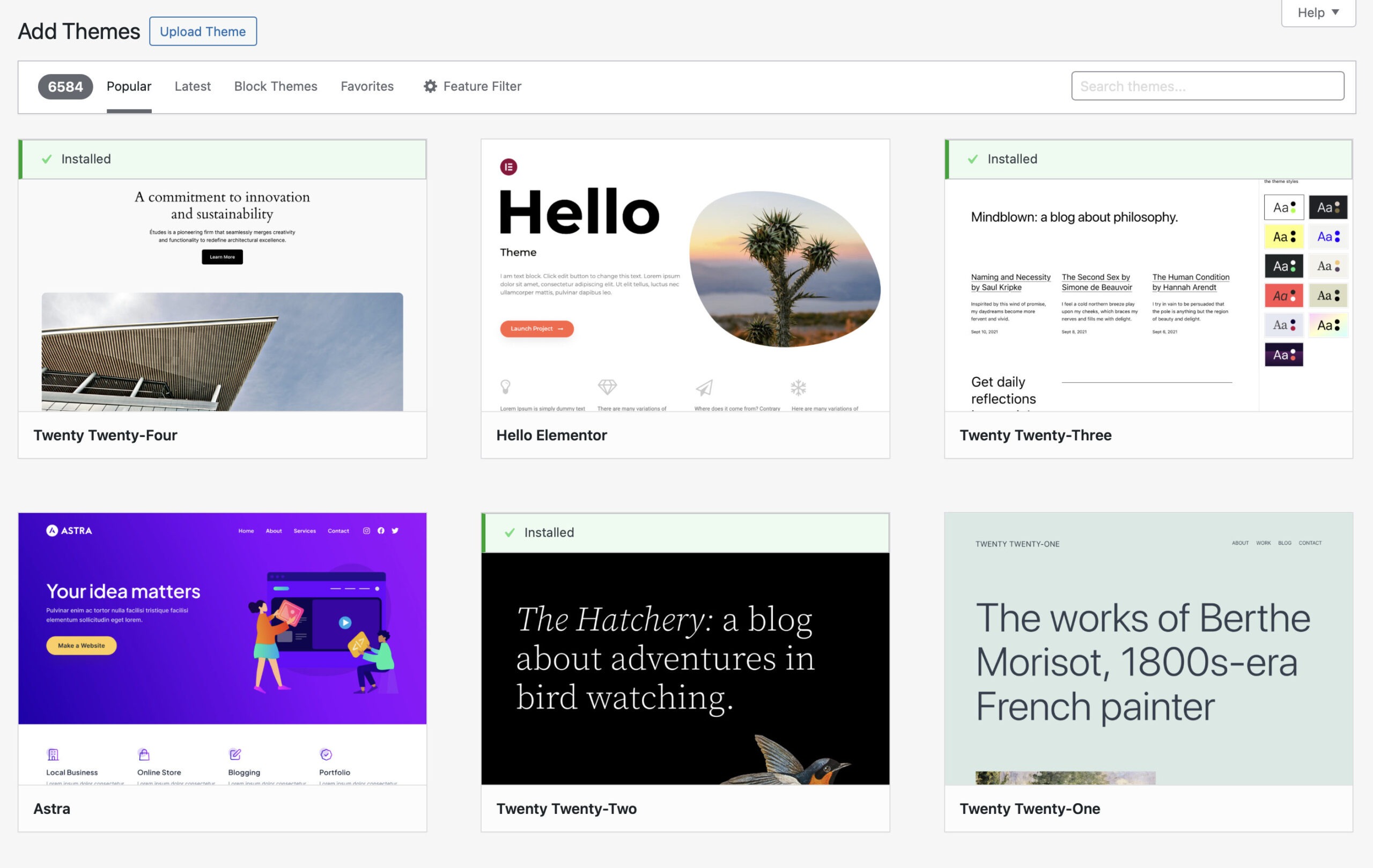
Elementor is extremely popular, in part because there’s a companion theme/gateway drug called Hello Elementor. It is the most popular third-party WordPress theme, as evidenced by its lofty position at the top of the WordPress theme download screen, surrounded by the official annual themes and one other third-party theme, Astra. (I actually really like Astra, because for the most part, it does things the WordPress way.)
Why is Hello Elementor so popular? Presumably people do like it. But I think it is also an example of what I would call the popularity feedback loop. It’s a natural, and harmful, side effect of a page like this, also commonly seen on e-commerce sites.
If you sort things by popularity, with the most popular items at the top, those are what people are going to see first. And most people don’t want to spend a lot of time considering options. They may trust popular opinion, or they may be too impatient to consider their options carefully, or they may just not care at all. So they click on the first thing that catches their attention, thereby making the popular thing even more popular, and dooming less popular options to oblivion, regardless of their quality.
The people choosing to default these lists to ranking by popularity may think they’re making an objectively straightforward choice, but they’re not considering how the popularity feedback loop might have much more of an effect on the rankings than quality, because they’re falsely assuming that people are making careful, rational choices.
There’s a large segment of the developer world that tries to avoid making “opinionated” decisions. But that’s a delusion. Every decision is opinionated. I would prefer to lean into it. Make the default a “recommended” list of options that have been evaluated by knowledgeable editors. Granted, that’s a lot more work, and is still subject to personal opinion and taste, but it could weed out the popular-but-garbage options that inevitably float to the top.
There’s another reason in this specific context why it matters. New users don’t understand the WordPress ecosystem. They don’t know about third-party themes and plugins. They don’t know what does or does not adhere to “the WordPress way.”
So, a new user comes in and wants to pick a theme for their site. Their eye is drawn to the Hello Elementor screenshot, which has been carefully designed to be attention-grabbing, especially compared to the rather pedestrian appearance of the official themes.
That’s all fine in and of itself. Third-party themes are great! But when you activate the Hello Elementor theme, it immediately starts prompting you to install the Elementor page builder plugin as well. If you’re not an experienced user, what are you supposed to do with this? You probably install it, of course. And now you’re in page builder land. It’s not WordPress anymore. The experience is completely different.
But what is it about page builders that’s so bad? (And this part really applies to Gutenberg to a large extent as well.) They’re supposed to be making it easier to design your web pages, right? Well… there’s only so much you can do to make designing a web page easier. There’s no way to deal with things like margins or padding without understanding what margins and padding are. The page builders end up being CSS GUIs. Maybe you’re not writing the code, but you still need to know the concepts to get anywhere. So you end up either creating a convoluted mess, or at best you do learn the concepts, but in a compromised way, that is inextricably tied to that page builder plugin. It’s lock-in.
I could go on, but I think there are two main ways to address the problem of the popularity feedback loop, at least as it applies specifically to WordPress themes, but also more generally:
Don’t default to a “most popular” view. I know it takes a lot more work, and is a lot more subjective, but the best default would be a “recommended” view. Some editorial decisions need to be made. Consider popularity, of course, but also consider context. Which themes are the best for a newcomer? Which ones offer the most pure WordPress experience?
Make the “most popular” list conditional. This is a more automated version of #1. Maybe you don’t have a carefully curated editorial list of recommendations, but at the very least, determine some criteria that can restrict what shows up in the list. For starters, maybe a theme cannot load with an admin notice pushing users to install a plugin. Would Hello Elementor be such a problem if it didn’t immediately lure new users into installing a page builder plugin too? Probably not.
Ultimately, I have my own selfish motivations in all of this. I develop a number of WordPress plugins myself, and I need to provide user support for them. And a significant percentage of my overall user support load — I would say it’s around 15-20% — is around conflicts with Elementor.
First off, this is not solving a problem. It’s making it easier to deal with the fallout of the problem.
Here’s the problem: bad actors steal credit card numbers, and sell batches of those credit card numbers to other bad actors who like to find ways to test out the credit card numbers to see if any are still active.
One way they like to do this is to find WooCommerce sites that sell cheap products — especially stickers, which are generally priced at $5 or less — and they use a script to spam the site with fake orders… well, real orders… for these cheap items, using fake contact information and the stolen credit card numbers. Most of them are already canceled and the transactions fail, but a small percentage of the cards are often still active, and the ability to place an order with them confirms it. I suspect the reason they place very small orders is that it’s easier for those transactions to go unnoticed by the real card owners.
Anyway, this is a problem I am seeing with increasing frequency on my clients’ WooCommerce sites, and there are generally two ways I address the problem.
First, I install Brian Henry’s WooCommerce Checkout Rate Limiter plugin. This can be very effective at throttling the scripts that place these huge blasts of orders from the same IP address, which leads to…
Second, I get the fake orders’ IP addresses and block them in the server’s firewall. You can get the customer IP address of any order in WooCommerce by clicking through to the detail page for an order. There are various ways to block IP addresses, including WordPress plugins, but I like to go straight to the source and block them in the ufw firewall right at the Linux OS level.
But the bad actors are perhaps becoming aware of these techniques to block them, and are modifying their tactics. I can see three ways they would do this, although I am only personally able to observe two of them: 1) slowing the rate of submissions, 2) spreading the submissions across multiple different sites, and 3) using different IP addresses. The first and third are the ones I can observe, of course, unless by chance the multiple sites are all maintained by me. (I do support a very large number of client sites, but not enough that this has happened yet.)
Anyway, we are now getting to the point of this post. I wanted a way to quickly see the customer IP address for a whole list of orders, instead of having to click through to each individual order’s detail page. Sure, I could fire up phpMyAdmin and do direct SQL queries, but I prefer the convenience of having this happen right within the WordPress admin. And so, I present to you a code snippet that will add an IP Address column to the WooCommerce admin Orders page:
That can go into your theme or a small plugin. The first block of code adds the IP Address column to the table on the Orders page, and the second block outputs the customer’s IP address in that cell in each row of the table.
Of course, this won’t stop bad actors from being bad actors. But it might help you reduce the number of fake orders your clients have to refund.
From its initial release as part of the WordPress core in version 5.0 in late 2018, up until early 2022, I adamantly refused to use Gutenberg. I felt its conceptual flaws and practical limitations were so profound and so obvious that I really could not believe this was going to be “the future of WordPress.” And now here we are.
In the spring of 2022 I finally relented, as at least the initial impression of the user interface had improved to a point where I felt I just needed to embrace it or move on. And so I created a new base “Block Theme” for future WordPress projects, and began building new client sites with it.
The past year and a half of dealing with Gutenberg more directly has been a painful rollercoaster of emotions, as I’ve tried repeated to convince myself it’s good, only to have it, once again, prove itself a hot mess of ill-conceived and barely-documented hacks.
Many times in the past 18 or so months I have contemplated abandoning WordPress for good, checking out ClassicPress and some other CMS options before falling back on giving Gutenberg another chance.
I’ve even considered writing my own Content Management System (CMS) [again; it’s something I specialized in before 2014]; switching to Drupal, for God’s sake (until I read that they’re porting Gutenberg for Drupal too… why why why?!); scrapping CMSes altogether in favor of just building sites with Bootstrap (and giving clients some rudimentary editing tools for the very few elements of their sites most of them actually modify post-launch); and even quitting the field entirely.
Frankly I don’t have the time or energy to make an extensive, coherent case for why Gutenberg is so fundamentally flawed; suffice to say it’s a combination of four main issues:
frustrations over its excessive reliance on React (the Flash of the 2020s) for so much of its functionality,
irritation at its embrace of the “make the interface seem simple by just hiding everything until the user hovers over the right magic spot” approach to UI/UX design,
trying to get a handle on how the damn thing works, due to its combination of woefully inadequate and outdated documentation, and the fact that it is constantly changing, in ways that break my code (which was written based on earlier assumptions about how things worked, because that was all I had to go on), and
The last one is really the killer, and it is only getting worse, because not only does the code — that fragile, convoluted, redundant code, stored in the database — become increasingly unmanageable the more you build your site, but WordPress is constantly pushing more of its structure into this disastrous framework (if you can call it a framework). The Site Editor is a true abomination that can’t possibly be useful to anyone… except possibly “no code” website builders. But honestly, if you can’t write code, you should just be using Squarespace instead of WordPress. You’ll be much happier, and so will your clients.
All of these issues probably stem from one even more basic to the whole discussion though: the creators of WordPress (especially imperious leader Matt Mullenweg) do not consider WordPress to be for what most of us “WordPress professionals” actually use it for. To them, it is blogging software. Period. But very few people who make a living in the WordPress ecosystem are using it to build blogs. Instead we are using it as a general-purpose CMS.
Gutenberg is adequate for a basic blog — in fact, I’m using it for this one, and I do prefer editing my posts in Gutenberg vs. Classic Editor. Its severe flaws and limitations don’t become readily apparent in the “basic blog” context.
There’s an argument to be made that Gutenberg really exists for WordPress.com to compete with the likes of Medium and Substack, and the industry of us web professionals who use the open source version are of no consequence to Matt’s vision for the platform.
Anyway, I have managed to launch about ten new client sites in the past year-plus using WordPress with Gutenberg, and every time I have had to face frustration and embarrassment as I acknowledge with clients the limitations of the tool, or sympathize with their frustrations in dealing with it as users.
My current project may be the last straw though. I’m two days away from launching the biggest site, by far, that I’ve built with Gutenberg. It’s over a year in the making, and now at the eleventh hour I am confronting the possibility of having to manually edit a huge number of posts in a CPT I created — and naively used the Block Editor to manage instead of just some ACF fields — because the client wants to change the default text sizes.
It’s possible this situation could be remedied by the merger of Block Patterns and Reusable Blocks that happened in WordPress 6.3, but guess what… we had already created all of this before that functionality was an option. I still haven’t had time to even figure out exactly what the implications of these 6.3 changes are, because I’ve been too busy just trying to build the site.
That’s where WordPress is really dying for me as a viable platform to work on. It’s supposed to be the foundation for what I do, but now the ground is constantly shifting beneath my feet. Gutenberg is making web development much harder and more frustrating, projects are taking longer, and it’s making me look incompetent and unprofessional to my clients. I’ve been a professional web developer since 1996; I’ve been using WordPress for projects since 2008, and almost exclusively since 2014. But now I don’t trust it anymore.
I’m in a position where I may (fingers crossed) be able to back off taking on any new freelance projects for the remainder of the year, once this site has launched. I am really hoping that’s the case, because it’s time for me to make a serious re-evaluation of whether or not I want to build any more WordPress sites in the future, and if not, I need to take that time to learn — or build — a new platform.
The great irony, of course, is that my business has increasingly been made up of selling and supporting my commercial WordPress plugin, ICS Calendar Pro. Fortunately, my work on that plugin has very little to do with, nor is significantly impacted by, the Gutenberg/Block Editor project, although that may change as WordPress continues to (d)evolve.
(Don’t even get me started on how bad Gutenberg is for responsive design.)